Every year, tens of thousands of new vulnerabilities are published. Security teams face an impossible task: patch everything, or figure out which ones actually matter. Machine learning is changing this equation by predicting which vulnerabilities are most likely to be exploited in the real world, before an attack happens.
The Challenge: Too Many Vulnerabilities, Too Little Time
In 2024 alone, over 29,000 new CVEs were published. Even well-resourced security teams can only remediate a fraction of these in any given sprint. Traditional prioritization methods rely heavily on CVSS scores, but a "Critical" CVSS rating doesn't necessarily mean a vulnerability will ever be exploited. The question teams really need answered is: what is the probability that this specific vulnerability will be weaponized?
This is exactly the question machine learning models are designed to answer.
What Data Do ML Models Use?
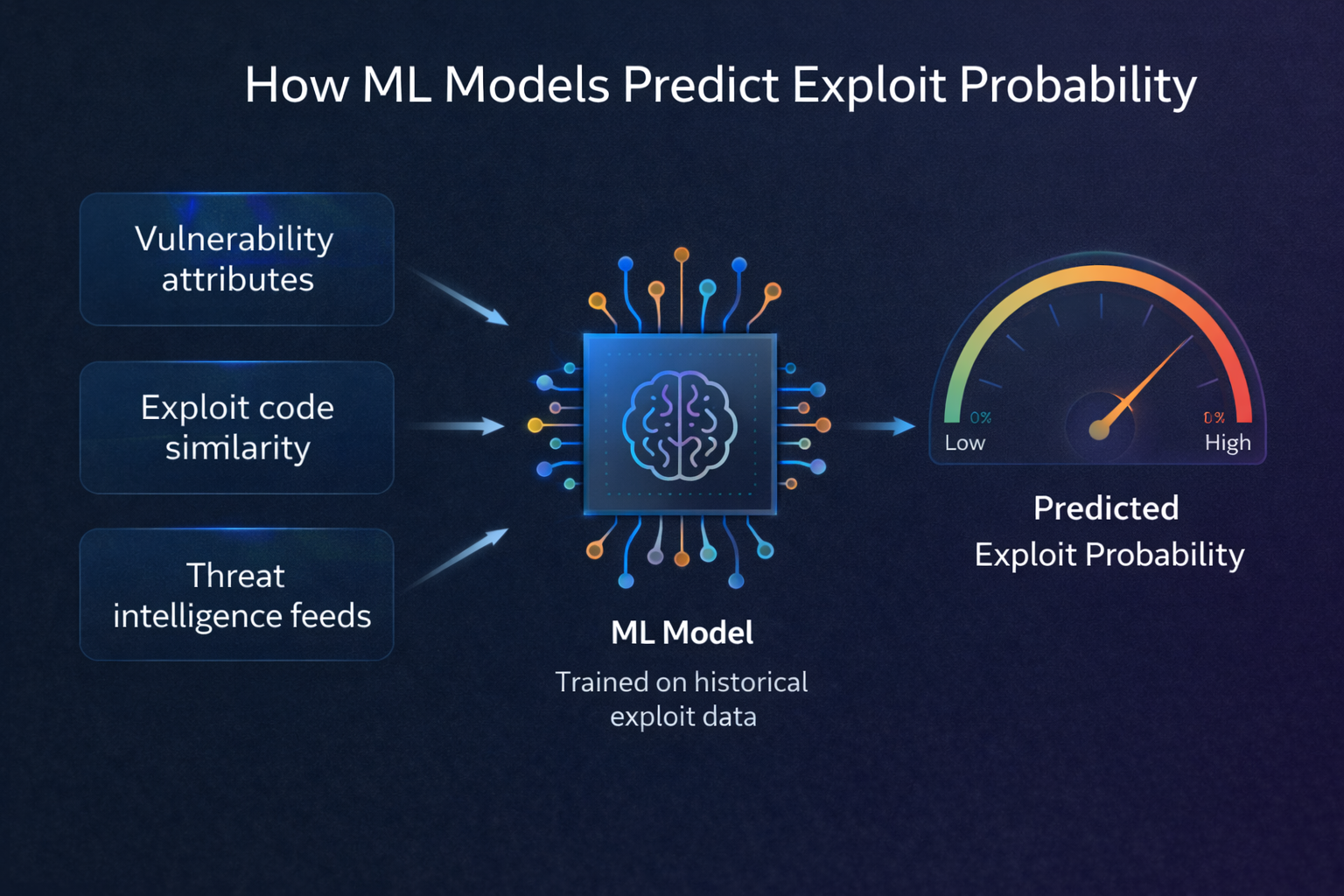
Exploit prediction models analyze a wide range of features extracted from each vulnerability. These features generally fall into several categories:
Vulnerability Characteristics
- CVSS vector components — Attack vector, complexity, privileges required, user interaction, and impact metrics provide the technical foundation.
- Vulnerability type (CWE) — Certain weakness types (buffer overflows, injection flaws, deserialization issues) have historically higher exploitation rates.
- Affected software — Vulnerabilities in widely deployed software (web browsers, operating systems, enterprise platforms) attract more attacker attention.
Threat Intelligence Signals
- Public exploit code — The existence of proof-of-concept exploits on platforms like Exploit-DB or GitHub dramatically increases the likelihood of exploitation.
- Dark web mentions — References to a CVE in underground forums or marketplaces signal active interest from threat actors.
- Social media activity — Spikes in discussion about a vulnerability on security-focused social channels often precede exploitation attempts.
Temporal Patterns
- Time since disclosure — Most exploited vulnerabilities are weaponized within the first 30 days of public disclosure.
- Patch availability — Unpatched vulnerabilities with available exploit code represent the highest risk window.
- Historical exploitation velocity — How quickly similar vulnerabilities have been exploited in the past.
How the Models Work
Modern exploit prediction systems typically use ensemble methods that combine multiple machine learning algorithms for more robust predictions:
Gradient Boosted Trees (XGBoost, LightGBM) are the workhorses of exploit prediction. They excel at handling the mix of numerical and categorical features found in vulnerability data, and they naturally capture complex interactions between features. For example, a model might learn that a buffer overflow (CWE-119) in an internet-facing web server with a low attack complexity has a very different exploit probability than the same CWE type in an internal library requiring local access.
Random Forests provide a complementary perspective, offering strong performance with built-in feature importance rankings. This interpretability is critical for security teams who need to understand why a vulnerability scored high, not just that it did.
Neural networks can capture subtle, non-linear patterns in the data, particularly when processing unstructured text from vulnerability descriptions, advisories, and threat reports.
Training and Validation
The models are trained on historical data: thousands of past vulnerabilities where the outcome (exploited or not exploited) is known. This creates a supervised learning problem where the model learns which combinations of features most strongly predict real-world exploitation.
Validation is critical. The best systems use time-based splits, training on older data and testing on more recent vulnerabilities, to ensure the model generalizes to new, unseen CVEs. Cross-validation techniques like k-fold help assess model stability and prevent overfitting to the training data.
Key metrics include:
- Precision — When the model says a vulnerability will be exploited, how often is it correct?
- Recall — Of all vulnerabilities that were actually exploited, how many did the model correctly flag?
- AUC-ROC — The overall ability of the model to distinguish between exploited and non-exploited vulnerabilities across all threshold settings.
From Prediction to Prioritization
A raw exploit probability score is valuable, but it becomes truly actionable when combined with organizational context. A vulnerability with a 40% exploit probability on an internet-facing payment server is far more urgent than one with an 80% probability on an isolated test machine.
This is where ML-powered scoring platforms add the most value: they combine the statistical exploit prediction with asset criticality, network exposure, industry-specific threat patterns, and compliance requirements to produce a single, actionable priority score that tells security teams exactly where to focus.
The Future of Exploit Prediction
ML models for exploit prediction are continuously improving. Emerging approaches include:
- Real-time model updates — Continuously retraining models as new threat intelligence arrives, rather than relying on periodic batch updates.
- Industry-specific models — Training specialized models for healthcare, finance, government, and other sectors where threat patterns differ significantly.
- Graph-based analysis — Modeling relationships between vulnerabilities, software dependencies, and threat actors as a graph to uncover hidden risk connections.
As these techniques mature, the gap between "vulnerabilities that look dangerous on paper" and "vulnerabilities that will actually be used in attacks" will continue to narrow, giving security teams an ever-sharper lens for prioritization.
See ML-powered scoring in action
Exploit Score uses purpose-built ML models trained on real-world exploit data to predict which vulnerabilities will be weaponized next.
Request a Demo